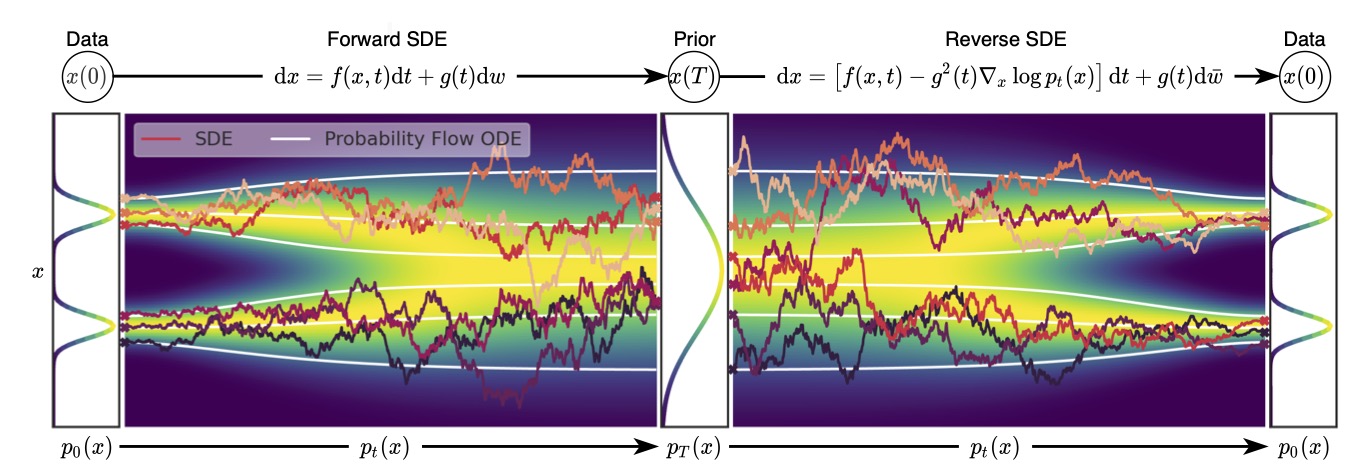
Score-based generative models (SBMs) and diffusion models rely on stochastic differential equations (SDEs) to model data distributions. However, while SDEs introduce randomness in sample trajectories, they can be converted into an equivalent ordinary differential equation (ODE) that retains the same probability density evolution. This ODE, known as the Probability Flow ODE , enables deterministic sampling while preserving the learned data distribution.
This post will:
Explain how SDE-based models generate samples
Derive Probability Flow ODE from Fokker-Planck theory
Provide an intuitive understanding of why this works
Give a Python implementation for deterministic sampling
A stochastic differential equation (SDE) is used to describe how data evolves over time:
\[
dx = f(x, t) dt + g(t) dW
\]
where:
\(f(x, t)\) is the drift term (deterministic evolution).
\(g(t) dW\) is the diffusion term (random noise from a Wiener process \(dW\)).
\(p_t(x)\) is the time-dependent probability density of \(x_t\).
Since SDEs include random noise , different samples follow different trajectories even if they start at the same initial condition.
The Key to Probability Density EvolutionAlthough each sample follows a random trajectory , the probability density function \(p_t(x)\) follows a deterministic evolution governed by the Fokker-Planck equation (FPE) :
$$
\frac{\partial p_t(x)}{\partial t} = -\nabla \cdot (f(x, t) p_t(x)) + \frac{1}{2} g^2(t) \nabla^2 p_t(x)
$$
The first term\(-\nabla \cdot (f(x, t) p_t(x))\) describes the effect of the drift term \(f(x, t)\) on the probability density.
The second term\(\frac{1}{2} g^2(t) \nabla^2 p_t(x)\) captures how diffusion smooths out the density over time.
Even though each particle moves randomly, the overall probability distribution \(p_t(x)\) evolves in a deterministic manner.
Since the probability density \(p_t(x)\) follows a deterministic equation (FPE), there should exist a corresponding deterministic process that moves samples in a way that preserves the same \(p_t(x)\).
This motivates the idea of a Probability Flow ODE :
\[
dx = v(x, t) dt
\]
where \(v(x, t)\) is a velocity field ensuring that the samples evolve according to the same probability density as the SDE, which is
importtorchfromtorchdiffeqimportodeintdefprobability_flow_ode(x,t,score_model):score=score_model(x,t)# Compute score function s_t(x)drift=f(x,t)-0.5*g(t)**2*scorereturndrift# Solve the ODE to generate samplesx_generated=odeint(probability_flow_ode,x_init,t_space)
Key difference from SDE sampling :
No randomness → Every run gives identical outputs.
Faster sampling → Fewer steps needed than stochastic diffusion.
Below are the expressions for the original distribution, the Langevin (diffusion) process, the DDPM reverse diffusion SDE, and the corresponding probability flow ODE for DDPM sampling.
Solving this ODE from \( t=1 \) (Gaussian noise) to \( t=0 \) yields samples that follow the target distribution.
These expressions form the basis for diffusion-based generative modeling—from the formulation of the target distribution to sampling via both stochastic reverse diffusion and its deterministic ODE counterpart.
importtorchimporttorch.nnasnnclassDiffusionBlock(nn.Module):def**init**(self,nunits):super(DiffusionBlock,self).**init**()self.linear=nn.Linear(nunits,nunits)defforward(self,x:torch.Tensor):x=self.linear(x)x=nn.functional.relu(x)returnxclassDiffusionModel(nn.Module):def**init**(self,nfeatures:int,nblocks:int=2,nunits:int=64):super(DiffusionModel,self).**init**()self.inblock=nn.Linear(nfeatures+1,nunits)self.midblocks=nn.ModuleList([DiffusionBlock(nunits)for_inrange(nblocks)])self.outblock=nn.Linear(nunits,nfeatures)defforward(self,x:torch.Tensor,t:torch.Tensor)->torch.Tensor:val=torch.hstack([x,t])# Add t to inputsval=self.inblock(val)formidblockinself.midblocks:val=midblock(val)val=self.outblock(val)returnvalmodel=DiffusionModel(nfeatures=2,nblocks=4)device="cuda"model=model.to(device)importtorch.optimasoptimnepochs=100batch_size=2048loss_fn=nn.MSELoss()optimizer=optim.Adam(model.parameters(),lr=0.001)scheduler=optim.lr_scheduler.LinearLR(optimizer,start_factor=1.0,end_factor=0.01,total_iters=nepochs)forepochinrange(nepochs):epoch_loss=steps=0foriinrange(0,len(X),batch_size):Xbatch=X[i:i+batch_size]timesteps=torch.randint(0,diffusion_steps,size=[len(Xbatch),1])noised,eps=noise(Xbatch,timesteps)predicted_noise=model(noised.to(device),timesteps.to(device))loss=loss_fn(predicted_noise,eps.to(device))optimizer.zero_grad()loss.backward()optimizer.step()epoch_loss+=losssteps+=1print(f"Epoch {epoch} loss = {epoch_loss/steps}")defsample_ddpm(model,nsamples,nfeatures):"""Sampler following the Denoising Diffusion Probabilistic Models method by Ho et al (Algorithm 2)"""withtorch.no_grad():x=torch.randn(size=(nsamples,nfeatures)).to(device)xt=[x]fortinrange(diffusion_steps-1,0,-1):predicted_noise=model(x,torch.full([nsamples,1],t).to(device))# See DDPM paper between equations 11 and 12x=1/(alphas[t]**0.5)*(x-(1-alphas[t])/((1-baralphas[t])**0.5)*predicted_noise)ift>1:# See DDPM paper section 3.2.# Choosing the variance through beta_t is optimal for x_0 a normal distributionvariance=betas[t]std=variance**(0.5)x+=std*torch.randn(size=(nsamples,nfeatures)).to(device)xt+=[x]returnx,xt
importtorchimportmatplotlib.pyplotaspltdeffunnel_score(x,z):"""Compute the score function (gradient of log-density) of the funnel distribution."""score_x=-x/torch.exp(z)score_z=-z+0.5*x**2*torch.exp(-z)returntorch.stack([score_x,score_z],dim=1)deflangevin_sampling_funnel(num_samples=10000,lr=0.001,num_steps=1500,noise_scale=0.001):"""Sample from the funnel distribution using Langevin dynamics."""# Initialize samples from a normal distributionsamples=torch.randn(num_samples,2)trajectory=[samples.clone()]# Store trajectoryfor_inrange(num_steps):x,z=samples[:,0],samples[:,1]score=funnel_score(x,z)samples=samples+lr*score+math.sqrt(2*noise_scale)*torch.randn_like(samples)trajectory.append(samples.clone())# Store trajectory stepreturnsamples,trajectory# Sample using Langevin dynamicssamples,trajectory=langevin_sampling_funnel()# Convert trajectory to numpy for visualizationtrajectory_np=[step.numpy()forstepintrajectory]# Plot final distributionplt.figure(figsize=(6,6))plt.scatter(samples[:,0],samples[:,1],alpha=0.5,s=0.1)plt.title("Final Sampled Distribution from VP-SDE")plt.xlabel("X-axis")plt.ylabel("Y-axis")plt.axis("equal")plt.show()
Every SDE can be converted into a Probability Flow ODE.
The deterministic ODE preserves the same probability density as the SDE.
Probability Flow ODE allows for efficient, repeatable sampling.
ODE solvers can be used instead of SDE solvers for generative modeling.
By leveraging Probability Flow ODE, we gain a powerful tool for deterministic yet efficient sampling in deep generative models . 🚀
Song et al., "Score-Based Generative Modeling through Stochastic Differential Equations," NeurIPS 2021
Chen et al., "Neural ODEs," NeurIPS 2018
Fluid mechanics: Continuity equation and probability flow
"The Probability Flow ODE is Provably Fast"Authors: Sitan Chen, Sinho Chewi, Holden Lee, Yuanzhi Li, Jianfeng Lu, Adil Salim
Summary: This paper provides the first polynomial-time convergence guarantees for the probability flow ODE implementation in score-based generative modeling. The authors develop novel techniques to study deterministic dynamics without contractivity.
Link:arXiv:2305.11798
"Convergence Analysis of Probability Flow ODE for Score-based Generative Models"Authors: Daniel Zhengyu Huang, Jiaoyang Huang, Zhengjiang Lin
Summary: This work studies the convergence properties of deterministic samplers based on probability flow ODEs, providing theoretical bounds on the total variation between the target and generated distributions.
Link:arXiv:2404.097302. Practical Implementations and Tutorials:
"On the Probability Flow ODE of Langevin Dynamics"Author: Mingxuan Yi
Summary: This blog post offers a numerical approach using PyTorch to simulate the probability flow ODE of Langevin dynamics, providing insights into practical implementation.
Link:Mingxuan Yi's Blog
"Generative Modeling by Estimating Gradients of the Data Distribution"Author: Yang Song
Summary: This post discusses learning score functions (gradients of log probability density functions) on noise-perturbed data distributions and generating samples with Langevin-type sampling.
Link:Yang Song's Blog3. Advanced Topics and Related Methods:
"An Introduction to Flow Matching"Authors: Cambridge Machine Learning Group
Summary: This blog post introduces Flow Matching, a generative modeling paradigm combining aspects from Continuous Normalizing Flows and Diffusion Models, offering a unique perspective on generative modeling.
Link:Cambridge MLG Blog
"Flow Matching: Matching Flows Instead of Scores"Author: Jakub M. Tomczak
Summary: This article presents a different perspective on generative models with ODEs, discussing Continuous Normalizing Flows and Probability Flow ODEs.
Link:Jakub M. Tomczak's Blog







💬 Comments Share your thoughts!