Understanding Latent Diffusion Models (LDMs): A Comprehensive Guide¶
1. Introduction¶
Latent Diffusion Models (LDMs) have revolutionized the field of generative AI by significantly improving efficiency and control in image generation tasks. Unlike traditional diffusion models that operate in pixel space, LDMs perform the diffusion process in a compressed latent space, reducing computational overhead while maintaining high-quality results. This blog explores the fundamental concepts of LDMs, their architecture, training process, and practical applications in image editing and style transfer.
2. 1. What Are Latent Diffusion Models (LDMs)?¶
LDMs are a class of diffusion models designed to operate in a lower-dimensional latent space rather than directly on high-dimensional pixel data. This key innovation allows them to be computationally efficient while retaining the expressive power of traditional diffusion models.
2.1 Key Concepts of LDMs¶
- Latent Space Diffusion: Instead of applying noise and denoising directly on images, LDMs first compress the image into a latent space using a pre-trained Variational Autoencoder (VAE). The diffusion process then occurs in this latent space.
- U-Net for Denoising: LDMs utilize a U-Net-based architecture to learn the denoising process and reconstruct the original latent representation.
- Cross-Attention for Conditional Control: By incorporating a cross-attention mechanism, LDMs can accept various forms of input conditions, such as text prompts, image guides, or segmentation masks.
- Efficient Computation: By reducing the dimensionality of the data before diffusion, LDMs significantly lower computational requirements compared to full-resolution diffusion models.

3. Conditional Generating¶
Beyond the capabilities of latent diffusion, another significant contribution is the implementation of conditional generation.
Let's take text-to-image generation as an example:
Let \(\tau_\theta(y)\) be a encoder (like the clip or orther pretrained models), \(\tau_\theta\) maps the condition \(y\) into the space \(R^{M\times d}\), and then use cross attention in the UNet to combine the condition in the model, which looks like

The overall framework consists of two phases:
- Training
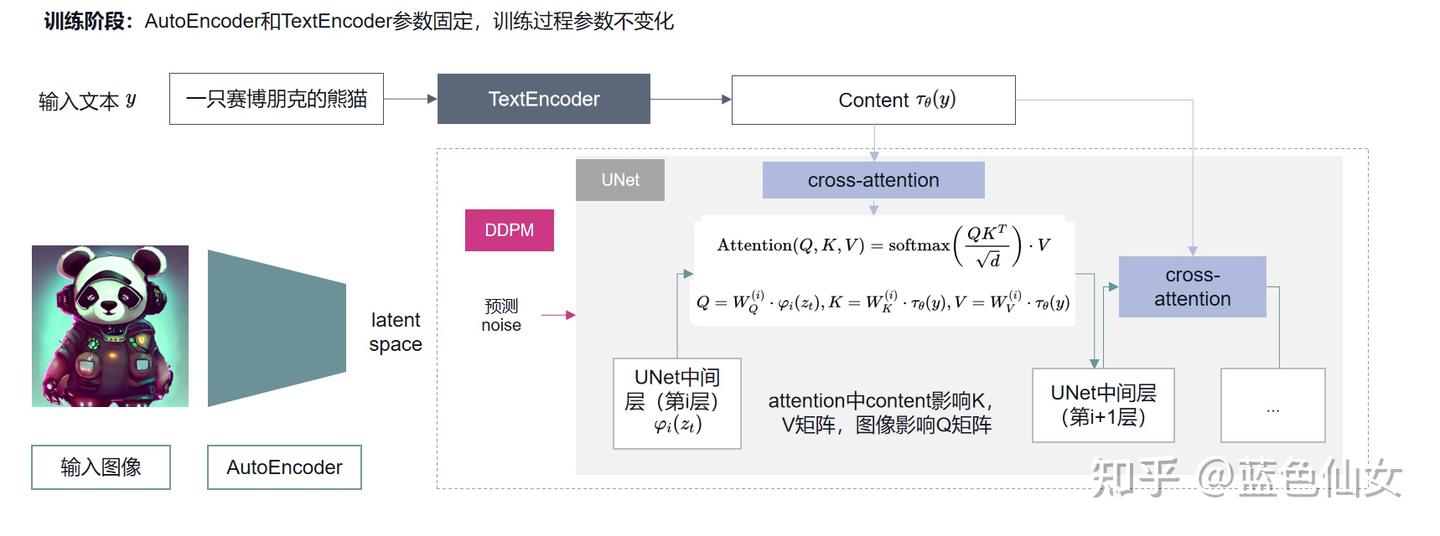
- Inference
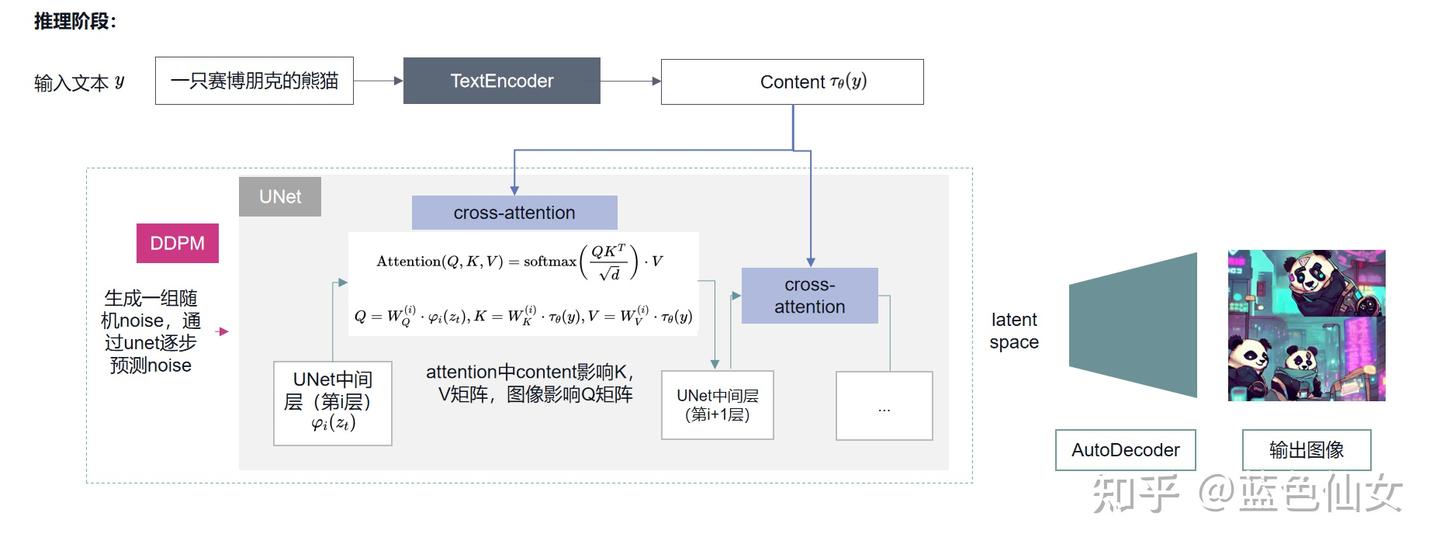
The training process must be jointly performed with the condition encoding network. When using a pretrained network for condition encoding, it can remain fixed while the training focuses on aligning the latent space with that of the pretrained conditioning model.
4. 2. Training and Inference in LDMs¶
The training and inference processes of LDMs involve multiple stages, primarily leveraging a VAE for encoding-decoding and a diffusion model for denoising.
4.1 (1) Training Process¶
4.1.1 Train the VAE¶
- The VAE consists of an encoder that compresses an input image into a latent representation \( z \).
- A decoder reconstructs the image from \( z \), ensuring the latent space preserves meaningful image information.
It has two types of VAEs
4.1.1.1 VQ-VAE¶
It is identical to the VQ-GAN architecture. For more details, please refer to the VQ-GAN article.
4.1.1.2 KL-VAE¶
This variant is a modification of VQ-GAN, where the quantizer module is replaced with a standard KL divergence loss. This simplifies the overall framework to a combination of VAE + GAN.
The loss can be represented as:
$$ \mathcal{L} = \frac{1}{N} \sum_{i=1}^{N} | x_i - \hat{x}i |^2+ \sum \lambda_l | \phi_l(x) - \phi_l(G(z)) |2^2 + \frac{1}{2} \sum $$ Refer }^{d} (1 + \log \sigma_{i,j}^2 - \mu_{i,j}^2 - \sigma_{i,j}^2)+ L_{advLatent Diffusion for more details about the coding. Here is the overall structure of the KL-VAE

4.1.2 Train the Latent Diffusion Model¶
- Noise is gradually added to the latent representation \( z \), following a Gaussian noise schedule.
-
The U-Net model learns to denoise and recover the original latent representation. Most steps are similar to those in DDPM. However, in this case, different types of conditions are processed and fed into the model. Here's a concise summary of the model's key components:
-
Input Definitions:
- Latent and Spatial Condition: $$ h_0 = \operatorname{concat}(z,\, c_{\text{concat}}) $$
- Time and Class Embedding: $$ \text{emb} = \phi(t) + \phi(y) $$
-
Context for Cross-Attention: $$ \text{context} = c_{\text{crossattn}} $$
-
Model Operation:
- The module that processes these inputs is defined as: $$ h = \operatorname{module}(h_0,\, \text{emb},\, \text{context}) $$
- Within the module:
- The embedding \( \text{emb} \) is added to the concatenated input \( h_0 \).
- Cross-attention is applied using the context \( c_{\text{crossattn}} \) (with \( c_{\text{crossattn}} \) serving as both keys and values) to fuse the sequential information with the spatial representation.
This sophisticated framework enables seamless integration of latent features, spatial conditioning, sequential context, and temporal and class information.
Below are visualizations of the Diffusion model framework:

graph LR
subgraph Image Processing
direction LR
A[down sample layer 1] --> B[SpatialTransformer] --> C[down sample layer 2]
end
subgraph Text Conditioning
direction BT
F["A white cat sitting on a chair"] --> E[FrozenCLIPEmbedder] --> D[content]
end
D -->|Conditioning| B


4.2 (2) Inference Process¶
- Start with Random Noise: Generate a noisy latent variable \( z_T \).
- Denoising Through U-Net: The trained U-Net progressively removes noise, reconstructing a meaningful latent representation \( z_0 \).
- Decode Back to Image: The VAE decoder converts the denoised latent representation into a final high-resolution image.
This workflow enables fast and high-quality image synthesis, forming the backbone of models like Stable Diffusion.
5. 3. Applications of LDMs¶
LDMs enable a range of advanced applications in image generation and editing. Below, we explore two key applications: image editing and style transfer.
5.1 (1) Image Editing with LDMs¶
LDMs provide powerful image editing capabilities, including Inpainting and Outpainting, by leveraging latent space manipulations.
5.1.1 A. Inpainting (Filling Missing Regions)¶
- Goal: Fill missing parts of an image naturally while keeping the existing content unchanged.
- Process:
- Encode the image into latent space.
- Apply noise selectively to the missing region.
- Use the U-Net denoising model to reconstruct plausible content.
- Decode the latent representation back into an image.
📌 Real-world example: Adobe Photoshop’s "Generative Fill" uses similar techniques for intelligent image restoration.
5.1.2 B. Outpainting (Expanding Image Boundaries)¶
- Goal: Extend an image beyond its original borders while preserving its consistency.
- Process:
- Encode the original image.
- Initialize the extended region with random noise.
- Perform controlled denoising while maintaining visual coherence.
- Decode the expanded latent space back into a complete image.
📌 Real-world example: OpenAI’s DALL·E 2 uses outpainting for creative image expansion.
5.2 (2) Style Transfer with LDMs¶
Style transfer refers to transforming an image into a new artistic style while maintaining its structural content. LDMs achieve this through two main approaches:
5.2.1 A. Direct Latent Space Manipulation¶
- Process:
- Encode the image into latent space.
- Introduce a style prompt (e.g., "Van Gogh style").
- Modify the denoising process with a cross-attention mechanism to enforce the style.
- Decode the final image.
📌 Application: Stable Diffusion enables users to generate images in diverse artistic styles through text prompts.
5.2.2 B. Fine-tuning with DreamBooth or ControlNet¶
- DreamBooth:
- Fine-tunes an LDM with a few style-specific images to learn and replicate custom styles.
-
Useful for custom artistic portrait generation.
-
ControlNet:
- Guides the diffusion process using structural constraints like depth maps, edge detection, or pose estimation.
- Enables precise style transfer with structural preservation.
📌 Application: ControlNet is extensively used for anime-style conversions and photo-to-painting transformations.
Refer latent diffusion model hands on for deep understanding of the codes.
6. 4. Key Advantages of LDMs¶
| Feature | Description |
|---|---|
| Computational Efficiency | LDMs perform diffusion in a compressed latent space, reducing the cost significantly. |
| High-Quality Image Generation | Produces highly detailed and realistic images. |
| Flexible Conditioning | Allows fine-grained control through text prompts, sketches, depth maps, etc. |
| Versatile Applications | Used in text-to-image generation, inpainting, style transfer, and more. |
7. Conclusion¶
Latent Diffusion Models (LDMs) have emerged as a groundbreaking approach in AI-generated content. By performing diffusion in latent space, they enhance efficiency, improve image quality, and enable advanced conditional control mechanisms. Their applications range from text-to-image generation to professional-grade image editing and style transfer.
With continuous advancements, LDM-based models like Stable Diffusion are shaping the future of generative AI, making high-quality image synthesis accessible to a broad audience.
8. Further Reading¶
- 📄 High-Resolution Image Synthesis with Latent Diffusion Models - The original LDM paper by Rombach et al.
- 🛠️ Stable Diffusion GitHub - Open-source implementation of LDMs.
- 🎨 ControlNet for Stable Diffusion - Advanced conditioning techniques for precise control.
💬 Comments Share your thoughts!