Scalable Diffusion Models with Transformers (DiT)¶
- Year: March 2023
- Authors:
- William Peebles
- DiT model (UC Berkeley)
- SORA project (OpenAI)
- Saining Xie
- DiT model (New York University)
- ResNeXt
- Cambrian-1 with Yann LeCun
- Main Contributions:
- Replaced the U-Net backbone with transformers
- Analyzed scalability properties
- Repository: https://github.com/facebookresearch/DiT/tree/main
1. Diffusion Transformer Design¶
The transformer diffusion is also trained with the latent diffusion model. Thus, the transformer diffusion is designed on the latent space.
1.1 Patchify¶
- Converts spatial input into a sequence of \(T\) tokens.
- Suppose the input size is [64, 64, 4], \(p=16\). For each \(16\times16\) square, we flatten it into a single token with a linear embedding layer. In total, we obtain \(64\times 64 / (p^2) = 16\) tokens. The output shape should be [16, d].
- In the design, the patch size \(p\) is regarded as a parameter.
We can use conv2d to perform patchification, followed by flattening and transposing to reshape the output.
1.2 Positional Encoding¶
Similar to the standard sine-cosine positional encoding, we can also use conv2d for positional encoding.
In transformer models, positional encoding is used to inject information about the position of tokens in a sequence, as the model itself doesn't inherently capture positional information. A common method is to use sinusoidal functions to generate these encodings. The formulas for sine and cosine positional encodings are as follows:
For a given position \( \text{pos} \) and embedding dimension \( i \):
- When \( i \) is even:
- When \( i \) is odd:
Here, \( d_{\text{model}} \) represents the dimensionality of the model's embeddings. These functions use different frequencies to encode each dimension, allowing the model to distinguish between different positions in the sequence. This approach was introduced in the "Attention Is All You Need" paper.
2. DiT Block Design¶
The core challenge is to design how to incorporate conditional information such as:
- Timestep \(t\)
- Class label \(c\)
- Guided text
- Guided spatial information such as depth, etc.
To implement this, the paper designs four different blocks to accept the conditions.
2.1 In-context Conditioning¶
Similar to the cls token in ViT, treat the embeddings of \(t\) and \(c\) as two additional tokens in the input sequence:
Then the input sequence is passed through a transformer encoder to extract context information.
2.2 Cross Attention Block¶
Similar to the Latent Diffusion latent diffusion hands-on

The \(t\) and \(c\) are concatenated as a length-two sequence and act as \(K\) and \(V\) in the cross-attention block, as shown in the above picture.
2.3 Adaptive Layer Norm (adaLN)¶
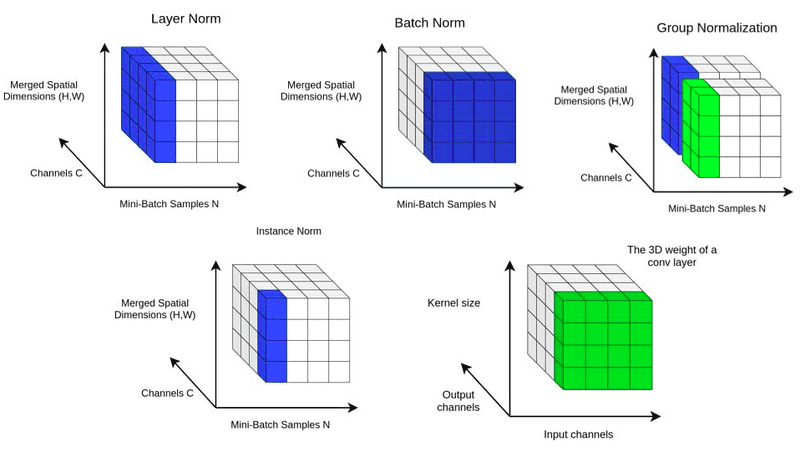
Borrowing ideas from StyleGAN's AdaIN, here is a comparison of Adaptive Layer Normalization (adaLN) in DiT and Adaptive Instance Normalization (AdaIN) in StyleGAN in tabular format:
| Feature | adaLN (DiT) | AdaIN (StyleGAN) |
|---|---|---|
| Purpose | Modulates transformer layers based on conditioning input (e.g., class labels, text embeddings). | Transfers style by aligning content feature statistics to match style feature statistics. |
| Normalization Scope | Normalizes across the entire layer (layer normalization). | Normalizes each feature channel independently per instance. (instance normalization) |
| Mathematical Formula | \( o_i = \gamma(y) \cdot \frac{x_i - \mu}{\sigma + \epsilon} + \beta(y) \) | \( o_i = \sigma(y) \cdot \frac{x_i - \mu(x)}{\sigma(x) + \epsilon} + \mu(y) \) |
| Parameter Modulation | \( \gamma \) and \( \beta \) are dynamically generated from a conditioning input \( y \). | \( \mu(y) \) and \( \sigma(y) \) are extracted from the style input \( y \). |
| Dependency | Learns conditioning through a neural network (e.g., MLP). | Uses statistics (mean & variance) directly from the style input. |
| Application | Used in transformer-based models like DiT to condition the model on auxiliary data (e.g., text, class labels). | Used in StyleGAN for style transfer and control of image synthesis. |
Here adaLN_modulation predicts the parameters \(\alpha_1\), \(\alpha_2\), \(\beta_1\), \(\beta_2\), \(\gamma_1\), \(\gamma_2\).
The DiTBlock with Adaptive Layer Norm Zero (adaLN-Zero) can be mathematically represented by the following function:
- Self attention
- Feedforward (MLP) Update
2.4 adaLN Zero Initialization¶
Assuming that zero initialization for residual networks is beneficial, we add the parameter \(scale\) to control the effects of adaLN. Initially, we set all the parameters of linear layers to 0.
2.5 Overall Structure of DiT¶
The structure of DiT is quite simple:
- Patchify the input \(x\), which has the shape [B, C, H, W].
- Apply position embedding of shape [B, T, D] on the patched tokens.
- Apply class/label embedding of shape [B, D] on the patched tokens.
- Combine time and class embedding \(c = t + y\).
- Process through the attention blocks.
- Apply the final layer to re-patchify.
- Convert to the original shape [B, C', H, W].
3. Results¶
- Larger size improves FID.


- With the same computational cost, larger models perform better.

- State-of-the-art results
 |
 |
|---|---|
💬 Comments Share your thoughts!