encoder predicted the mean and log variance. And then saples by reparametrization.
The encoder outputs a hidden representation, which is then split into a mean (\(\mu\)) and log-variance (\(\log \sigma^2\)):
\[
h = \text{Encoder}(x)
\]
\[
\mu, \log\sigma^2 = \text{split}(h)
\]
The log-variance is clamped to prevent extreme values:
The code is same as that in the LDM, see more details in
Here is an updated table summarizing the VAEEncoder feature map shapes, including the network components (e.g., ResNet blocks, self-attention layers, convolutions, etc.) at each stage.
Stage
Resolution (H × W)
Channels
Downsampling Applied?
Network Components
Input Image
\( H \times W \)
3
No
Raw image input
Conv In
\( H \times W \)
128
No
\(3 \times 3\) Conv layer
Downsampling Level 1
\( H \times W \) → \( \frac{H}{2} \times \frac{W}{2} \)
classVAEDecoder(torch.nn.Module):def__init__(self,ch=128,out_ch=3,ch_mult=(1,2,4,4),num_res_blocks=2,resolution=256,z_channels=16,dtype=torch.float32,device=None):super().__init__()self.num_resolutions=len(ch_mult)self.num_res_blocks=num_res_blocksblock_in=ch*ch_mult[self.num_resolutions-1]curr_res=resolution//2**(self.num_resolutions-1)# z to block_inself.conv_in=torch.nn.Conv2d(z_channels,block_in,kernel_size=3,stride=1,padding=1,dtype=dtype,device=device)# middleself.mid=torch.nn.Module()self.mid.block_1=ResnetBlock(in_channels=block_in,out_channels=block_in,dtype=dtype,device=device)self.mid.attn_1=AttnBlock(block_in,dtype=dtype,device=device)self.mid.block_2=ResnetBlock(in_channels=block_in,out_channels=block_in,dtype=dtype,device=device)# upsamplingself.up=torch.nn.ModuleList()fori_levelinreversed(range(self.num_resolutions)):block=torch.nn.ModuleList()block_out=ch*ch_mult[i_level]fori_blockinrange(self.num_res_blocks+1):block.append(ResnetBlock(in_channels=block_in,out_channels=block_out,dtype=dtype,device=device))block_in=block_outup=torch.nn.Module()up.block=blockifi_level!=0:up.upsample=Upsample(block_in,dtype=dtype,device=device)curr_res=curr_res*2self.up.insert(0,up)# prepend to get consistent order# endself.norm_out=Normalize(block_in,dtype=dtype,device=device)self.conv_out=torch.nn.Conv2d(block_in,out_ch,kernel_size=3,stride=1,padding=1,dtype=dtype,device=device)self.swish=torch.nn.SiLU(inplace=True)defforward(self,z):# z to block_inhidden=self.conv_in(z)# middlehidden=self.mid.block_1(hidden)hidden=self.mid.attn_1(hidden)hidden=self.mid.block_2(hidden)# upsamplingfori_levelinreversed(range(self.num_resolutions)):fori_blockinrange(self.num_res_blocks+1):hidden=self.up[i_level].block[i_block](hidden)ifi_level!=0:hidden=self.up[i_level].upsample(hidden)# endhidden=self.norm_out(hidden)hidden=self.swish(hidden)hidden=self.conv_out(hidden)returnhidden
The VAEDecoder reconstructs an image from a latent space representation by progressively upsampling and refining features through ResNet blocks, self-attention, and convolutional layers.
classAttnBlock(torch.nn.Module):def__init__(self,in_channels,dtype=torch.float32,device=None):super().__init__()self.norm=Normalize(in_channels,dtype=dtype,device=device)self.q=torch.nn.Conv2d(in_channels,in_channels,kernel_size=1,stride=1,padding=0,dtype=dtype,device=device)self.k=torch.nn.Conv2d(in_channels,in_channels,kernel_size=1,stride=1,padding=0,dtype=dtype,device=device)self.v=torch.nn.Conv2d(in_channels,in_channels,kernel_size=1,stride=1,padding=0,dtype=dtype,device=device)self.proj_out=torch.nn.Conv2d(in_channels,in_channels,kernel_size=1,stride=1,padding=0,dtype=dtype,device=device)defforward(self,x):hidden=self.norm(x)q=self.q(hidden)k=self.k(hidden)v=self.v(hidden)b,c,h,w=q.shapeq,k,v=map(lambdax:einops.rearrange(x,"b c h w -> b 1 (h w) c").contiguous(),(q,k,v))hidden=torch.nn.functional.scaled_dot_product_attention(q,k,v)# scale is dim ** -0.5 per defaulthidden=einops.rearrange(hidden,"b 1 (h w) c -> b c h w",h=h,w=w,c=c,b=b)hidden=self.proj_out(hidden)returnx+hidden
classPatchEmbed(nn.Module):""" 2D Image to Patch Embedding"""def__init__(self,img_size:Optional[int]=224,patch_size:int=16,in_chans:int=3,embed_dim:int=768,flatten:bool=True,bias:bool=True,strict_img_size:bool=True,dynamic_img_pad:bool=False,dtype=None,device=None,):super().__init__()self.patch_size=(patch_size,patch_size)ifimg_sizeisnotNone:self.img_size=(img_size,img_size)self.grid_size=tuple([s//pfors,pinzip(self.img_size,self.patch_size)])self.num_patches=self.grid_size[0]*self.grid_size[1]else:self.img_size=Noneself.grid_size=Noneself.num_patches=None# flatten spatial dim and transpose to channels last, kept for bwd compatself.flatten=flattenself.strict_img_size=strict_img_sizeself.dynamic_img_pad=dynamic_img_padself.proj=nn.Conv2d(in_chans,embed_dim,kernel_size=patch_size,stride=patch_size,bias=bias,dtype=dtype,device=device)defforward(self,x):B,C,H,W=x.shapex=self.proj(x)ifself.flatten:x=x.flatten(2).transpose(1,2)# NCHW -> NLCreturnx
Use the convolution to do the patchify that convert the original image from [B,C,H,W] to \([B,N,C]\), where \(N=\frac{H}{\text{patch size}}\times\frac{W}{\text{patch size}}=\frac{H\times W}{4}\). The convolutional kernel size is \(patch_size\times patch_size\).
classTimestepEmbedder(nn.Module):"""Embeds scalar timesteps into vector representations."""def__init__(self,hidden_size,frequency_embedding_size=256,dtype=None,device=None):super().__init__()self.mlp=nn.Sequential(nn.Linear(frequency_embedding_size,hidden_size,bias=True,dtype=dtype,device=device),nn.SiLU(),nn.Linear(hidden_size,hidden_size,bias=True,dtype=dtype,device=device),)self.frequency_embedding_size=frequency_embedding_size@staticmethoddeftimestep_embedding(t,dim,max_period=10000):""" Create sinusoidal timestep embeddings. :param t: a 1-D Tensor of N indices, one per batch element. These may be fractional. :param dim: the dimension of the output. :param max_period: controls the minimum frequency of the embeddings. :return: an (N, D) Tensor of positional embeddings. """half=dim//2freqs=torch.exp(-math.log(max_period)*torch.arange(start=0,end=half,dtype=torch.float32)/half).to(device=t.device)args=t[:,None].float()*freqs[None]embedding=torch.cat([torch.cos(args),torch.sin(args)],dim=-1)ifdim%2:embedding=torch.cat([embedding,torch.zeros_like(embedding[:,:1])],dim=-1)iftorch.is_floating_point(t):embedding=embedding.to(dtype=t.dtype)returnembeddingdefforward(self,t,dtype,**kwargs):t_freq=self.timestep_embedding(t,self.frequency_embedding_size).to(dtype)t_emb=self.mlp(t_freq)returnt_emb
The timestep embedding function generates a vector representation of time \( t \) using sinusoidal embeddings. The formula can be rewritten as a single vector equation.
Embedding as a Vector
For a given timestep \( t \), the embedding vector \( E_t \) is computed as:
# codeclassDismantledBlock(nn.Module):"""A DiT block with gated adaptive layer norm (adaLN) conditioning."""ATTENTION_MODES=("xformers","torch","torch-hb","math","debug")def__init__(self,hidden_size:int,num_heads:int,mlp_ratio:float=4.0,attn_mode:str="xformers",qkv_bias:bool=False,pre_only:bool=False,rmsnorm:bool=False,scale_mod_only:bool=False,swiglu:bool=False,qk_norm:Optional[str]=None,dtype=None,device=None,**block_kwargs,):super().__init__()assertattn_modeinself.ATTENTION_MODESifnotrmsnorm:self.norm1=nn.LayerNorm(hidden_size,elementwise_affine=False,eps=1e-6,dtype=dtype,device=device)else:self.norm1=RMSNorm(hidden_size,elementwise_affine=False,eps=1e-6)self.attn=SelfAttention(dim=hidden_size,num_heads=num_heads,qkv_bias=qkv_bias,attn_mode=attn_mode,pre_only=pre_only,qk_norm=qk_norm,rmsnorm=rmsnorm,dtype=dtype,device=device)ifnotpre_only:ifnotrmsnorm:self.norm2=nn.LayerNorm(hidden_size,elementwise_affine=False,eps=1e-6,dtype=dtype,device=device)else:self.norm2=RMSNorm(hidden_size,elementwise_affine=False,eps=1e-6)mlp_hidden_dim=int(hidden_size*mlp_ratio)ifnotpre_only:ifnotswiglu:self.mlp=Mlp(in_features=hidden_size,hidden_features=mlp_hidden_dim,act_layer=nn.GELU(approximate="tanh"),dtype=dtype,device=device)else:self.mlp=SwiGLUFeedForward(dim=hidden_size,hidden_dim=mlp_hidden_dim,multiple_of=256)self.scale_mod_only=scale_mod_onlyifnotscale_mod_only:n_mods=6ifnotpre_onlyelse2else:n_mods=4ifnotpre_onlyelse1self.adaLN_modulation=nn.Sequential(nn.SiLU(),nn.Linear(hidden_size,n_mods*hidden_size,bias=True,dtype=dtype,device=device))self.pre_only=pre_onlydefpre_attention(self,x:torch.Tensor,c:torch.Tensor):assertxisnotNone,"pre_attention called with None input"ifnotself.pre_only:ifnotself.scale_mod_only:shift_msa,scale_msa,gate_msa,shift_mlp,scale_mlp,gate_mlp=self.adaLN_modulation(c).chunk(6,dim=1)else:shift_msa=Noneshift_mlp=Nonescale_msa,gate_msa,scale_mlp,gate_mlp=self.adaLN_modulation(c).chunk(4,dim=1)qkv=self.attn.pre_attention(modulate(self.norm1(x),shift_msa,scale_msa))returnqkv,(x,gate_msa,shift_mlp,scale_mlp,gate_mlp)else:ifnotself.scale_mod_only:shift_msa,scale_msa=self.adaLN_modulation(c).chunk(2,dim=1)else:shift_msa=Nonescale_msa=self.adaLN_modulation(c)qkv=self.attn.pre_attention(modulate(self.norm1(x),shift_msa,scale_msa))returnqkv,Nonedefpost_attention(self,attn,x,gate_msa,shift_mlp,scale_mlp,gate_mlp):assertnotself.pre_onlyx=x+gate_msa.unsqueeze(1)*self.attn.post_attention(attn)x=x+gate_mlp.unsqueeze(1)*self.mlp(modulate(self.norm2(x),shift_mlp,scale_mlp))returnxdefforward(self,x:torch.Tensor,c:torch.Tensor)->torch.Tensor:assertnotself.pre_only(q,k,v),intermediates=self.pre_attention(x,c)attn=attention(q,k,v,self.attn.num_heads)returnself.post_attention(attn,*intermediates)
It is a normal self attention network but with different layernorm layers. Also, it cobines the linear projections of Q,K, and V together into a single linear projection.
defcropped_pos_embed(self,hw):assertself.pos_embed_max_sizeisnotNonep=self.x_embedder.patch_size[0]h,w=hw# patched sizeh=h//pw=w//passerth<=self.pos_embed_max_size,(h,self.pos_embed_max_size)assertw<=self.pos_embed_max_size,(w,self.pos_embed_max_size)top=(self.pos_embed_max_size-h)//2left=(self.pos_embed_max_size-w)//2spatial_pos_embed=rearrange(self.pos_embed,"1 (h w) c -> 1 h w c",h=self.pos_embed_max_size,w=self.pos_embed_max_size,)spatial_pos_embed=spatial_pos_embed[:,top:top+h,left:left+w,:]spatial_pos_embed=rearrange(spatial_pos_embed,"1 h w c -> 1 (h w) c")returnspatial_pos_embed
This function extracts a cropped positional embedding from a larger precomputed embedding, ensuring spatial alignment in Transformers for varying input sizes.
Key Steps:
1. Compute Patched Size – Converts input dimensions to patch-based resolution.
2. Validate Size – Ensures it does not exceed the stored max embedding size.
3. Center Crop – Extracts the relevant portion of the positional embedding.
4. Format Adjustment – Reshapes from (1, HW, C) → (1, H, W, C) → (1, hw, C).
Purpose:
- Adapts positional embeddings for different resolutions.
- Maintains spatial awareness in ViT/DiT models.
- Enables flexibility without retraining embeddings.
defforward_core_with_concat(self,x:torch.Tensor,c_mod:torch.Tensor,context:Optional[torch.Tensor]=None)->torch.Tensor:ifself.register_length>0:context=torch.cat((repeat(self.register,"1 ... -> b ...",b=x.shape[0]),contextifcontextisnotNoneelsetorch.Tensor([]).type_as(x)),1)# context is B, L', D# x is B, L, Dforblockinself.joint_blocks:context,x=block(context,x,c=c_mod)x=self.final_layer(x,c_mod)# (N, T, patch_size ** 2 * out_channels)returnx
It handles the case when context is None, the empty tensor will be created as context.
If register_length>0, it will create 'register_length's tokens appending before the context sequence. Like
defblock_mixing(context,x,context_block,x_block,c):assertcontextisnotNone,"block_mixing called with None context"context_qkv,context_intermediates=context_block.pre_attention(context,c)x_qkv,x_intermediates=x_block.pre_attention(x,c)o=[]fortinrange(3):o.append(torch.cat((context_qkv[t],x_qkv[t]),dim=1))q,k,v=tuple(o)attn=attention(q,k,v,x_block.attn.num_heads)context_attn,x_attn=(attn[:,:context_qkv[0].shape[1]],attn[:,context_qkv[0].shape[1]:])ifnotcontext_block.pre_only:context=context_block.post_attention(context_attn,*context_intermediates)else:context=Nonex=x_block.post_attention(x_attn,*x_intermediates)returncontext,x
As shown above, the block mixing is a attention block, that first process context and x seperately, and concat them together to do self attention, (which can be considered as the cross attention from each other by concating the information in the K,V).
It need further to check what is the context_block, and x_block, which are same attention network structure
classDismantledBlock(nn.Module):ATTENTION_MODES=("xformers","torch","torch-hb","math","debug")def__init__(self,hidden_size:int,num_heads:int,mlp_ratio:float=4.0,attn_mode:str="xformers",qkv_bias:bool=False,pre_only:bool=False,rmsnorm:bool=False,scale_mod_only:bool=False,swiglu:bool=False,qk_norm:Optional[str]=None,dtype=None,device=None,**block_kwargs,):super().__init__()assertattn_modeinself.ATTENTION_MODESifnotrmsnorm:self.norm1=nn.LayerNorm(hidden_size,elementwise_affine=False,eps=1e-6,dtype=dtype,device=device)else:self.norm1=RMSNorm(hidden_size,elementwise_affine=False,eps=1e-6)self.attn=SelfAttention(dim=hidden_size,num_heads=num_heads,qkv_bias=qkv_bias,attn_mode=attn_mode,pre_only=pre_only,qk_norm=qk_norm,rmsnorm=rmsnorm,dtype=dtype,device=device)ifnotpre_only:ifnotrmsnorm:self.norm2=nn.LayerNorm(hidden_size,elementwise_affine=False,eps=1e-6,dtype=dtype,device=device)else:self.norm2=RMSNorm(hidden_size,elementwise_affine=False,eps=1e-6)mlp_hidden_dim=int(hidden_size*mlp_ratio)ifnotpre_only:ifnotswiglu:self.mlp=Mlp(in_features=hidden_size,hidden_features=mlp_hidden_dim,act_layer=nn.GELU(approximate="tanh"),dtype=dtype,device=device)else:self.mlp=SwiGLUFeedForward(dim=hidden_size,hidden_dim=mlp_hidden_dim,multiple_of=256)self.scale_mod_only=scale_mod_onlyifnotscale_mod_only:n_mods=6ifnotpre_onlyelse2else:n_mods=4ifnotpre_onlyelse1self.adaLN_modulation=nn.Sequential(nn.SiLU(),nn.Linear(hidden_size,n_mods*hidden_size,bias=True,dtype=dtype,device=device))self.pre_only=pre_onlydefpre_attention(self,x:torch.Tensor,c:torch.Tensor):assertxisnotNone,"pre_attention called with None input"ifnotself.pre_only:ifnotself.scale_mod_only:shift_msa,scale_msa,gate_msa,shift_mlp,scale_mlp,gate_mlp=self.adaLN_modulation(c).chunk(6,dim=1)else:shift_msa=Noneshift_mlp=Nonescale_msa,gate_msa,scale_mlp,gate_mlp=self.adaLN_modulation(c).chunk(4,dim=1)qkv=self.attn.pre_attention(modulate(self.norm1(x),shift_msa,scale_msa))returnqkv,(x,gate_msa,shift_mlp,scale_mlp,gate_mlp)else:ifnotself.scale_mod_only:shift_msa,scale_msa=self.adaLN_modulation(c).chunk(2,dim=1)else:shift_msa=Nonescale_msa=self.adaLN_modulation(c)qkv=self.attn.pre_attention(modulate(self.norm1(x),shift_msa,scale_msa))returnqkv,Nonedefpost_attention(self,attn,x,gate_msa,shift_mlp,scale_mlp,gate_mlp):assertnotself.pre_onlyx=x+gate_msa.unsqueeze(1)*self.attn.post_attention(attn)x=x+gate_mlp.unsqueeze(1)*self.mlp(modulate(self.norm2(x),shift_mlp,scale_mlp))returnxdefforward(self,x:torch.Tensor,c:torch.Tensor)->torch.Tensor:assertnotself.pre_only(q,k,v),intermediates=self.pre_attention(x,c)attn=attention(q,k,v,self.attn.num_heads)returnself.post_attention(attn,*intermediates)
Since in the mixing_block, only the pre_attention and the post_attention are called, Let's only look at these two functions only.
It take the idea of the adaIN from DiT paper. which modulate the shift and scale after the layer norm before and after the attention.
Also inferit from the idea of DiT, it use the gate parameter to control the strength of the residule network after the self attention of context and x, which hope in the initial stage, the increament component in residule block could be 0 to obtain the stability of the training.
In the Joint Block, only the pre_attention and post_attention are called.
The pre_attention did the linear transform and the layer norm of the Q,K,V in the self attention mechanics before sending to the attention function. The layer norm can be chosed from the standard layer normalization, or the RSM_layer normalization or just Identity
The post_attention did the linear transform of the output of the attention function. Increase the model capability, nothing special.
To have better prompt understanding, we used three text embedding models
clip_g.safetensors (openclip bigG, same as SDXL)
clip_l.safetensors (OpenAI CLIP-L, same as SDXL)
t5xxl.safetensors (google T5-v1.1-XXL)
sd3 prompt processing
The prompt processing in Stable Diffusion 3 involves multiple steps and components designed to transform text input into embedding representations suitable for image generation. Here is a summary of the process:
Text Encoding:
The input text is encoded using the CLIP model. There are two versions of the CLIP model: Clip_L and Clip_G, each generating embeddings of different dimensions.
Clip_L produces a 77x768 embedding matrix.
Clip_G produces a 75x768 embedding matrix.
Pooling Operation:
Pooling operations are applied to the CLIP embeddings to generate fixed-size vectors.
L_pool generates a 768-dimensional pooled vector.
G_pool generates a 1280-dimensional pooled vector.
Embedding Concatenation:
Embeddings from different sources are concatenated to create a richer representation.
L_pool and G_pool are concatenated to form a 2048-dimensional pooled embedding vector.
The embedding sequences from Clip_L and Clip_G are concatenated to produce a 154x4096 embedding matrix.
Padding and Alignment:
Zero padding (zeros padding) may be applied to ensure that the embedding sequences have consistent lengths.
For example, the embedding sequence from G is expanded from 75 to 154 to match the length of other embedding sequences.
Context Processing:
The final embedding representations are used to provide context for image generation.
These embeddings are fed into the T5 model or other generative models for further processing to generate images.
In summary, the prompt processing in Stable Diffusion 3 transforms text input into high-dimensional embedding representations through multiple steps. These representations are then used to generate images. The process involves the collaboration of multiple models, including CLIP and T5, to ensure that the generated images are highly relevant to the input text.
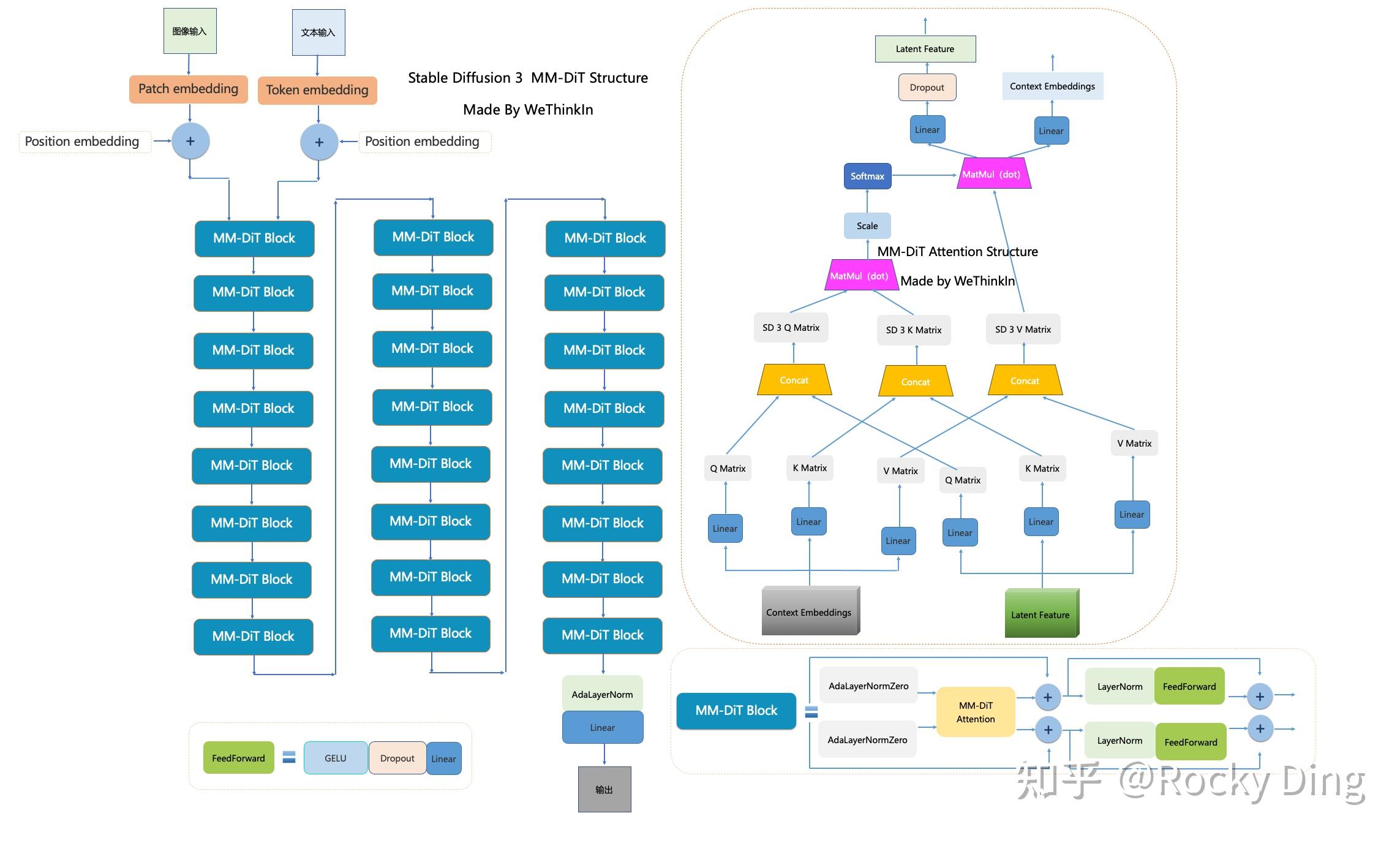
We have studied the network structure of the MM-DiT. To summary, the MM-DiT's contribution is
Use same idea of handling condition c by adaLN
cross attention for the context (text/sequential information) and latent feature x by the dual path. Handle context and x seperatly but fed into attention by concating
use cropping positional embedding to support different resolution
Let draw the overrall structure of the diffusion model
As mentioned in the above, the prompt will be processed into a pooled global embedding and a non-pooled sequential detail embedding. Consider both positive prompt and negative prompt, we will obtain two set of conditions
cond
context
y
uncond
context
y
In stable diffusion 3,
But in practice, the negative prompt is empty string, which take the effect of the CFG, classifier free guidance diffusion. That is, the negative is the case the condition is empty.
Have more details in guidance diffusion
Next, let's check the detailed sampling steps if we have the condition already.
```py3
def to_d(x, sigma, denoised):
"""Converts a denoiser output to a Karras ODE derivative."""
return (x - denoised) / append_dims(sigma, x.ndim)
@torch.no_grad()
@torch.autocast("cuda", dtype=torch.float16)
def sample_euler(model, x, sigmas, extra_args=None):
"""Implements Algorithm 2 (Euler steps) from Karras et al. (2022)."""
extra_args = {} if extra_args is None else extra_args
s_in = x.new_ones([x.shape[0]])
for i in range(len(sigmas) - 1):
sigma_hat = sigmas[i]
denoised = model(x, sigma_hat * s_in, **extra_args)
d = to_d(x, sigma_hat, denoised)
dt = sigmas[i + 1] - sigma_hat
# Euler method
x = x + d * dt
return x
```
The Euler method is a simple numerical integration technique used to solve ordinary differential equations (ODEs). The code you provided implements a modified Euler method for solving the Karras ODE in diffusion models. Below, I will compare this Euler-based sampler with the standard Euler method, highlighting the differences.
Standard Euler Method
The explicit (forward) Euler method is defined as:
\[
x_{t-1} = x_t + f(x_t, t) \cdot dt
\]
where:
\( x_t \) is the current state,
\( f(x_t, t) \) is the derivative (computed from an ODE),
\( dt \) is the step size.
This method is used to approximate the solution of an ODE by taking small discrete steps.
Equation in Diffusion Models
Diffusion models can be formulated as an ODE:
\( \frac{x_t - \text{denoised}(x_t)}{\sigma} \) acts as the ODE derivative.
\( dt \) is the time step, determined by the noise schedule.
This is an explicit Euler step applied to a diffusion model.
Feature
Standard Euler
Diffusion Euler (Karras ODE)
ODE Formulation
General-purpose ODE
Diffusion-specific ODE
Derivative Function \( f(x, t) \)
Predefined function
Computed via denoiser
Step Size \( dt \)
Fixed
Adaptive (determined by noise schedule)
Dynamical Behavior
General ODE integration
Guides noise removal
Goal
Solve ODE
Generate images from noise
Standard Euler computes derivatives directly from an ODE function \( f(x, t) \).
In contrast, Diffusion Euler estimates the derivative from the denoising model.
Standard Euler uses a fixed step size \( dt \), whereas Diffusion Euler uses an adaptive step size \( dt = \sigma_{t+1} - \sigma_t \).
This makes the diffusion process more flexible.
In diffusion models, the score function (or denoiser) acts as an implicit ODE solver.
The model learns how to remove noise at different levels, effectively solving the reverse SDE (stochastic differential equation) using an ODE approximation.
 Increase \(d\) can improve the performance as described in the above table.
Increase \(d\) can improve the performance as described in the above table.





💬 Comments Share your thoughts!