Flux.1
Code explain: https://zhuanlan.zhihu.com/p/741939590/ reading note: https://zhuanlan.zhihu.com/p/684068402?utm_source=chatgpt.com
network structure
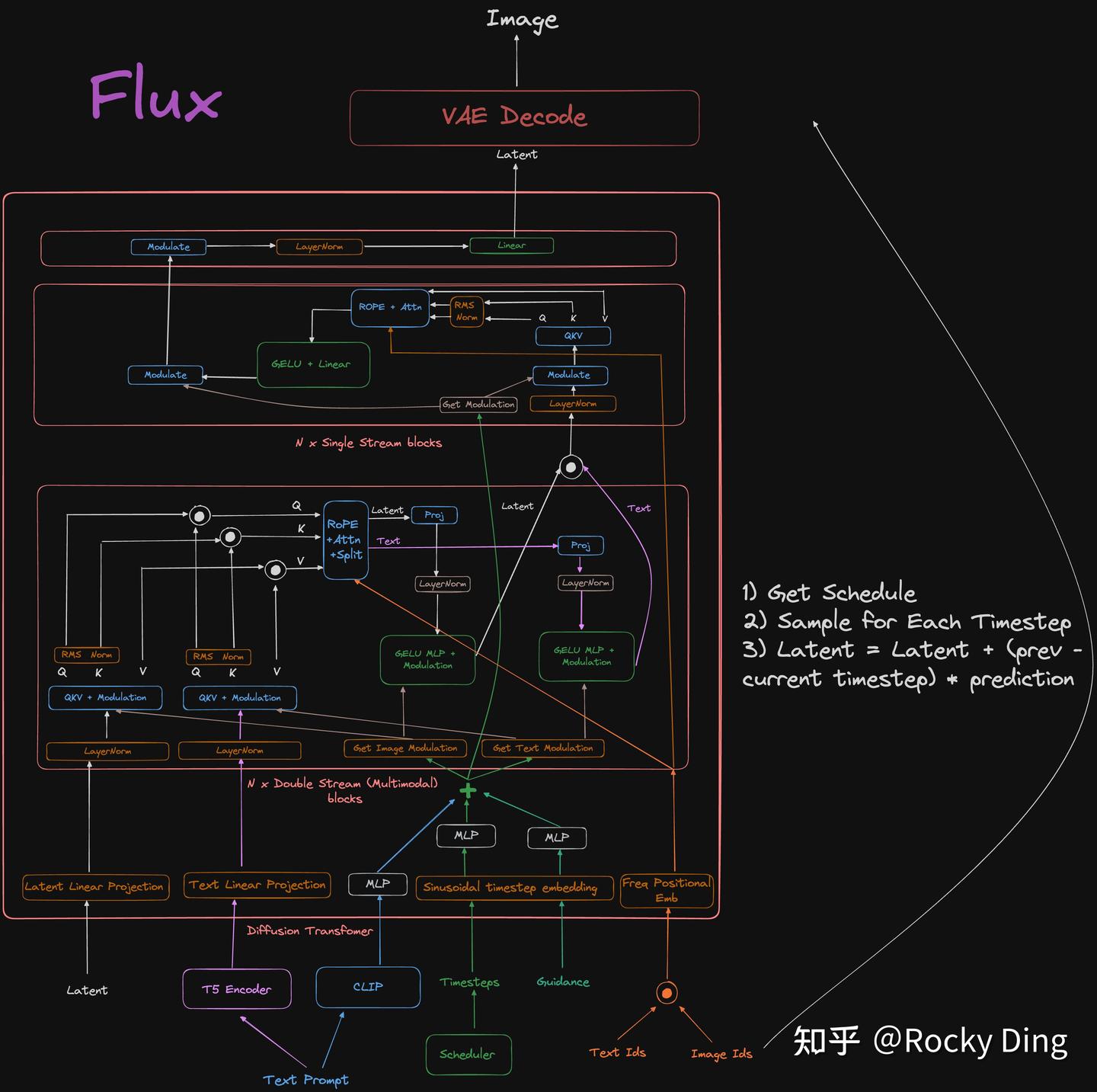
Code study¶
Next, let's study the code of flux.1 in details. Since the Flux only provided the inference code, we did not know how the model is trained. Let's just check how the model is sampled and try to guess how the model is trained.
We start with the sampling methods
1. Sampling¶
The flux sampling accept the following parameters:
2. time scheduling¶
2.1 time_shift 函数¶
数学表达式: $$ \text{time_shift}(\mu, \sigma, t) = \frac{e\mu}{e\mu + \left(\frac{1}{t} - 1\right)^\sigma} $$
参数说明: • \(\mu\):控制函数曲线的中心位置。 • \(\sigma\):控制函数曲线的陡峭程度。 • \(t\):输入的时间张量,取值范围为 \([0, 1]\)。
功能: • 对输入的时间 \(t\) 进行非线性变换,使其在 \([0, 1]\) 区间内重新分布。 • 当 \(\mu\) 增大时,函数曲线向右偏移;当 \(\sigma\) 增大时,函数曲线变得更陡峭。
2.2 get_lin_function 函数¶
数学表达式: $$ \text{get_lin_function}(x_1, y_1, x_2, y_2) = f(x) = m \cdot x + b $$ 其中: $$ m = \frac{y_2 - y_1}{x_2 - x_1}, \quad b = y_1 - m \cdot x_1 $$
参数说明: • \(x_1, y_1\):直线上的第一个点。 • \(x_2, y_2\):直线上的第二个点。 • \(x\):输入的自变量。
功能: • 根据两点 \((x_1, y_1)\) 和 \((x_2, y_2)\) 计算直线的斜率和截距,返回一个线性函数 \(f(x) = m \cdot x + b\)。也就是根据分辨率计算时间步长的调整参数。256 对应的 \(\mu\) 值为 0.5,4096 对应的 \(\mu\) 值为 1.15。
2.3 get_schedule 函数¶
数学表达式:
1. 生成时间步长:
$$
\text{timesteps} = \text{linspace}(1, 0, \text{num_steps} + 1)
$$
2. 如果需要调整时间步长:
$$
\mu = f(\text{image_seq_len}), \quad \text{timesteps} = \text{time_shift}(\mu, 1.0, \text{timesteps})
$$
其中 \(f\) 是由 get_lin_function 生成的线性函数:
$$
f(x) = m \cdot x + b, \quad m = \frac{\text{max_shift} - \text{base_shift}}{x_2 - x_1}, \quad b = \text{base_shift} - m \cdot x_1
$$
参数说明: • \(\text{num\_steps}\):时间步长的数量。 • \(\text{image\_seq\_len}\):图像序列的长度,用于计算 \(\mu\)。 • \(\text{base\_shift}\):时间调整的基础值。 • \(\text{max\_shift}\):时间调整的最大值。 • \(\text{shift}\):是否对时间步长进行调整。
功能:
1. 生成从 1 到 0 的等间隔时间步长。
2. 如果需要调整时间步长:
• 根据 \(\text{image\_seq\_len}\) 计算 \(\mu\)。
• 使用 time_shift 函数对时间步长进行非线性变换。
2.4 整体逻辑¶
- 生成时间步长: $$ \text{timesteps} = {1, 1 - \Delta, 1 - 2\Delta, \dots, 0}, \quad \Delta = \frac{1}{\text{num_steps}} $$
- 计算 \(\mu\): $$ \mu = f(\text{image_seq_len}), \quad f(x) = m \cdot x + b $$
- 调整时间步长:
$$
\text{timesteps} = \left{ \frac{e\mu}{e\mu + \left(\frac{1}{t} - 1\right)^\sigma} \mid t \in \text{timesteps} \right}
$$
调整后时间步长的效果

3. 图片和prompt预处理¶
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | |
不同于SD 3, 这里只用到两个text encoder, 一个是clip, 一个是t5,分别用于global的文本特征和局部的文本特征,也就是 'vec'和'txt',相对于SD 3,会更简洁。
同时这里增加了'img_ids'和'txt_ids',用来给图片和文本添加位置编码。其中'img_ids'是图片的坐标,'txt_ids'是文本的坐标,目前为0。
因为整张图片会被分成很多个\(2\times 2\) 的小块,这个'img_ids'记录的就是每个小块的编号,从而让模型知道这个小块在图片中的位置。
4. 去噪步骤¶
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
用数学公式表示就是:
where \(t_n,n=0,1,\ldots,N-1\) starts from 1 and ends at 0.
这是一个标准的Euler去噪步骤, 对应的ODE是
5. Flux Model¶
接下来我们看一下flux model 的网络结构,看它怎么处理图片以及condition的。它主要的结构包括 - guidance embedding & time embedding - positional encoding - double stream block - single stream block - output layer
1. Double Stream Block¶
1.1 1. 输入与参数定义¶
• 输入:
• 图像特征:\( \mathbf{X}_{\text{img}} \in \mathbb{R}^{B \times L_{\text{img}} \times D} \)
• 文本特征:\( \mathbf{X}_{\text{txt}} \in \mathbb{R}^{B \times L_{\text{txt}} \times D} \)
• 调制向量:\( \mathbf{v} \in \mathbb{R}^{B \times d} \)
• 位置编码:\( \mathbf{P} \in \mathbb{R}^{L \times d_p} \)
• 参数生成(通过 img_mod 和 txt_mod):
• 图像调制参数:
$$
(\mathbf{s}{\text{img}}^{(1)}, \mathbf{b}}}^{(1)}, g_{\text{img}}^{(1)}), \quad (\mathbf{s{\text{img}}^{(2)}, \mathbf{b})
$$
• 文本调制参数:
$$
(\mathbf{s}}}^{(2)}, g_{\text{img}}^{(2)}) = \text{img_mod}(\mathbf{v{\text{txt}}^{(1)}, \mathbf{b}}}^{(1)}, g_{\text{txt}}^{(1)}), \quad (\mathbf{s{\text{txt}}^{(2)}, \mathbf{b})
$$}}^{(2)}, g_{\text{txt}}^{(2)}) = \text{txt_mod}(\mathbf{v
1.2 2. 图像分支处理¶
1.2.1 (a) 特征调制¶
• 归一化: $$ \mathbf{X}{\text{img}}^{(1)} = \text{Norm}_1^{\text{img}}(\mathbf{X}) $$ • }仿射变换: $$ \tilde{\mathbf{X}}{\text{img}}^{(1)} = \left(1 + \mathbf{s}}}^{(1)} \right) \odot \mathbf{X{\text{img}}^{(1)} + \mathbf{b} $$}}^{(1)
1.2.2 (b) 生成Q/K/V¶
• 线性投影:
$$
\mathbf{Q}{\text{img}}, \mathbf{K}}}, \mathbf{V{\text{img}} = \text{split_heads}\left( \mathbf{W} \right)
$$
其中 }}^{qkv} \tilde{\mathbf{X}}_{\text{img}}^{(1)\( \mathbf{W}_{\text{img}}^{qkv} \in \mathbb{R}^{D \times 3HD} \),split_heads 将张量分割为多头形式。
1.2.3 (c) Q/K归一化¶
1.3 3. 文本分支处理¶
1.3.1 (a) 特征调制¶
• 归一化: $$ \mathbf{X}{\text{txt}}^{(1)} = \text{Norm}_1^{\text{txt}}(\mathbf{X}) $$ • }仿射变换: $$ \tilde{\mathbf{X}}{\text{txt}}^{(1)} = \left(1 + \mathbf{s}}}^{(1)} \right) \odot \mathbf{X{\text{txt}}^{(1)} + \mathbf{b} $$}}^{(1)
1.3.2 (b) 生成Q/K/V¶
• 线性投影: $$ \mathbf{Q}{\text{txt}}, \mathbf{K}}}, \mathbf{V{\text{txt}} = \text{split_heads}\left( \mathbf{W} \right) $$}}^{qkv} \tilde{\mathbf{X}}_{\text{txt}}^{(1)
1.3.3 (c) Q/K归一化¶
1.4 4. 跨模态注意力¶
1.4.1 (a) 拼接Q/K/V¶
1.4.2 (b) 注意力计算¶
$$ \text{Attn}(\mathbf{Q}, \mathbf{K}, \mathbf{V}, \mathbf{P}) = \text{Softmax}\left( \frac{\mathbf{Q} \mathbf{K}^\top}{\sqrt{d}} + \phi(\mathbf{P}) \right) \mathbf{V} $$ 其中 \( \phi(\mathbf{P}) \) 为位置编码的映射函数。
1.4.3 (c) 分割注意力结果¶
1.5 5. 残差连接与输出¶
1.5.1 (a) 图像分支更新¶
• 注意力残差: $$ \mathbf{X}{\text{img}} \leftarrow \mathbf{X}}} + g_{\text{img}}^{(1)} \cdot \mathbf{W{\text{img}}^{\text{proj}} \mathbf{A} $$ • }MLP残差: $$ \mathbf{X}{\text{img}} \leftarrow \mathbf{X}}} + g_{\text{img}}^{(2)} \cdot \text{MLP{\text{img}} \left( \left(1 + \mathbf{s}}}^{(2)} \right) \odot \text{Norm2^{\text{img}}(\mathbf{X} \right) $$}}) + \mathbf{b}_{\text{img}}^{(2)
1.5.2 (b) 文本分支更新¶
• 注意力残差: $$ \mathbf{X}{\text{txt}} \leftarrow \mathbf{X}}} + g_{\text{txt}}^{(1)} \cdot \mathbf{W{\text{txt}}^{\text{proj}} \mathbf{A} $$ • }MLP残差: $$ \mathbf{X}{\text{txt}} \leftarrow \mathbf{X}}} + g_{\text{txt}}^{(2)} \cdot \text{MLP{\text{txt}} \left( \left(1 + \mathbf{s}}}^{(2)} \right) \odot \text{Norm2^{\text{txt}}(\mathbf{X} \right) $$}}) + \mathbf{b}_{\text{txt}}^{(2)
1.6 符号说明¶
• \( \odot \): 逐元素乘法(Hadamard积) • \( \text{Norm} \): 归一化操作(如LayerNorm或RMSNorm) • \( \text{MLP} \): 多层感知机(通常为线性层 + 激活函数 + 线性层) • \( \mathbf{W}^{qkv}, \mathbf{W}^{\text{proj}} \): 可学习的投影矩阵 • \( g \): 门控标量(控制残差分支的权重)
1.7 总结¶
该模块通过跨模态注意力融合图像与文本特征,利用动态调制参数(由向量 \(\mathbf{v}\) 生成)对特征进行归一化和仿射变换,最终通过门控残差连接更新特征。数学公式完整描述了代码中的张量操作与信息流动。
💬 Comments Share your thoughts!